


医疗智能化离不开电子病历后结构化系统,电子病历的结构化是医疗信息化发展的一个重要环节,是打通医疗信息化壁垒,医疗数据互联互通的必由之路
然而,电子病历结构化面临着两大技术难点:
难度一:电子病历的输入问题
电子病历是体现医生诊治思路的重要文书,每位医生都有自己独特的病历书写习惯,如果采用固定的模板选项,则会严重影响医生的思维,而非结构化的自然语言描述又很难被计算机识别。如何能从“医生看懂”提升到“计算机能看懂”,需要计算机在浩如烟海的医疗知识中进行学习,才能全面、准确的理解电子病历中描述的内容。
两种输入汉字方法的比较 急性阑尾炎的主诉为例
自由化输入(包括拷贝复制法输入):
右下腹持续性疼痛4小时
选择性录入:
选择疼痛部位“右下腹、右上腹、脐下…”;
选择疼性质“持续性、转移性、…”;
选择疼痛种类“疼痛、刺痛、剧痛…”;
选择疼痛时间“1、2、3、4….”
选择时间单位“年、月、日、小时…”
难度二:文档格式多样性问题
各厂商研制的病历文档的类别多种多样,格式迥异;同时各类医疗文本格式也不尽相同,如病程录、治疗过程、巡查记录、化验单、入院记录等信息。格式不同,数据组合也会有很大的差别
如何能让计算机根据病历内容来深度语义理解,来抽取出相应的知识点,是计算机训练的重要课题
后结构化平台技术优势
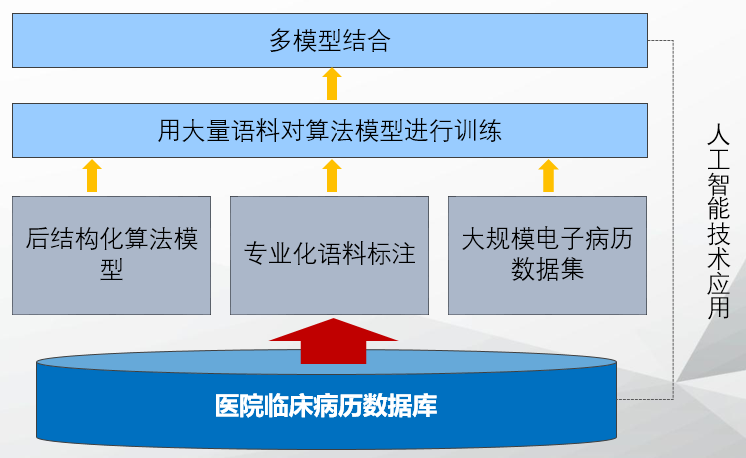
我们运用人工智能领域最新技术,对双向循环神经网络、条件随机场等算法进行了进一步改进,创造性的实现了通过融合多个模型进行结构化拆分的方法。 同时还构建了大规模的医疗语料知识库,并聘请医疗专业团队进行语义标注。得益于多模型融合技术和大规模标注语料库,算法的准确程度和分拆的专业可信程度都得到了显著的提升
我们的后结构化产品能识别不同厂商、不同科室、表达方式各不相同的病历文本
采用Transformer结合CRF
构建通用的智能电子病历后结构化平台
我们的电子病历后结构化平台,以大量临床数据为基础,采用全新的人工智能技术,建立不同的电子病历结构化模型,构建了通用的医疗电子文书解析平台
人工智能自然语言处理技术的全新的模
BiLSTM(双向循环神经网络)的引入,解决了同时考虑上下文信息的问题,而CRF(Conditional Random Fields,条件随机场)的引入则对标签的预测建立了约束条件,从而可以体现出标签之间相互影响的关系。
实践中,CRF应用在BiLSTM的顶层,即把BiLSTM的输出作为CRF的输入。这样就得到了当前最流行的方法:BiLSTM结合CRF算法。其中,BiLSTM的作用是感知;而CRF能学习上下文信息,结合输出层结果和标签序列的全局概率,预测出最大概率的标签序列。
人工智能自然语言处理技术的全新的模
我们在此基础上进行了进一步的改造。Transformer模型是最近一年多来NLP领域最重要的进展。与BiLSTM一样,Transformer模型可以对输入序列每个字之间的特征关系进行提取与捕捉。通过自注意力机制和对多个基本的编码器(Encoder)与解码器(Decoder)单元进行连续堆叠,Transformer模型可以发现单字在不同语境下的不同语义,从而实现了一词多义的区分,比BiLSTM具备更强的特征提取性能。
人工智能自然语言处理技术的全新的模
在实践中,我们只使用了Transformer的编码器部分(某种意义上说,更像是Bert,即双向Transformer的Encoder),通过多层的自注意力计算结合残差的计算,将最顶层的Encoder单元的输出作为CRF的输入,就得到命名实体的标签分类。
我们将电子病历中通过自然语言描述的人体部位、疾病名称、症状、化验项目、检查项目、手术、治疗等术语,界定为医学命名实体,通过上述Transformer结合CRF的算法,进行了实体识别及提取的试验。由于我们标注的词汇相对比较核心,即未包括各种修饰类的形容词,因此识别效果比之前的一些研究成果要高出很多。
Transformer结合CRF的算法,既克服了CRF算法难以识别上下文语义的缺点,又克服了BiLSTM结合CRF算法容易梯度消失和难以并行化计算的不足。有了这一算法的精准识别和提取,我们就可以在“电子病历结构化分拆系统”中进一步构造后结构化模板:即key或value包含一个或多个实体,再组合修饰词共同构成,从而实现电子病历的准确拆分

为什么要使用我们的产品?
1、提高评级-刚性需求
电子病历评级4级要求全院信息共享,越往后越注重数据对医疗的智能化的支撑作用。因而对电子病历信息数据的提取要求越高,颗粒度越细,甚至拆分到词汇,唯有这样的数据信息才能更好地被统计、分析、查找和再利用。使用我们的产品能轻松提高数据质量,从容面对评级。
2、实现医疗数据互联互通
基于电子病历的院内信息互联互通是电子病历应用水平评级的硬性要求,但实际上同一家医院内的不同系统之间的电子病历格式都可能不尽相同,而文档或段落粒度的病历数据可利用性差,不能完全满足互联互通的要求。借助于电子病历后结构化工具,将自然语言描述的电子病历转化成为结构化细粒度的数据,就可以实现院内医疗数据在字段级的互联互通。
3、助力电子病历质控
由于“人可读、机不可读”的特点,评价自然语言描述的病历的质量,往往需要消耗大量的人力资源。通过运用电子病历后结构化工具,就可以分解出构成电子病历的各结构化信息要素,结合行业标准,也就可以自动评判医生是否全面、完整的描述了治疗过程各方面情况,从而实现了病历质量评价的目标。
4、支持科研数据分析
临床科研分析所需要的关键数据可能淹没在通过自然语言描述的非结构化病历中,导致统计数据不准确、也不完整。科研人员如需提取病历中的关键信息,就需要人工阅读病历文本并进行查找,不但效率低下,且容易导致遗漏。有了后结构化助手,就可以快速提取出关键信息,构建结构化的电子病历数据用于统计分析。
5、积累结构化病历模板
基于“前结构化的模板”的电子病历系统会影响医生的思路,主要是因为实际上临床上可能出现的情况千差万别,而这类病历给出的可选项既不够全面,也不够灵活。因此,只有通过“后结构化”分拆了各科室、各专业的大量电子病历后,才能充分积累临床上遇到的各种情况及其对应的术语。这样形成的模板才是研发“结构化电子病历”的基础,因此“后结构化”是积累结构化电子病历模板的必由之路。
6、更多的应用领域
电子病历后结构化也可以为构建更加精细更加全面的患者画像、医疗数据知识图谱等数据知识库做支持,还可为临床辅助决策、治疗方案推荐、患者预后评估等系统作为数据的基础。
我们的产品优势?
识别不同各类病历文本
我们运用人工智能领域最新技术,对双向循环神经网络、条件随机场等算法进行了进一步改进, 创造性的实现了通过融合多个模型进行结构化拆分的方法。 我们还构建了大规模的医疗语料知识库,并聘请医疗专业团队进行语义标注。得益于多模型融合技术和大规模标注语料库,算法的准确程度和分拆的专业可信程度都得到了显著的提升, 这也使我们的后结构化产品能识别不同厂商、不同科室、表达方式各不相同的病历文本。
无需对接医疗设备
各个医院使用各种不同医疗设备接口各不相同,对接接口非常麻烦。我们的系统无需接口,不与医院现有的系统对接,单独使用。只要导入自然语言描述的临床医疗文本,即可自动生成结构化数据。
现场部署+云系统,任意选择
我们提供两种使用方式以供选择,其一为现场独立部署,单独安装在独立设备上,无需接口,不影响医院其他设备使用;其二采用云端服务,操作简便,成本更底。
量身定制的医疗软件
根据各个医院不同场景不同科室的具体需求,进行个性化定制型再开发,满足医院特定需求,提供更贴心的服务。



140万,河北省儿童医院实验室信息管理系统(LIS系统)中标(成交)结果公告
120万,检验项目服务委托竞争性磋商公告
17万,新疆医科大学第一附属医院lis维保项目中标(成交)结果公告
176万,青岛大学附属医院(平度)医院信息系统功能升级二次招标中标公告
10万,泉州市妇幼保健院(泉州市儿童医院)国家传染病智能监测预警接口项目
2098万,北大荒集团神经精神病防治院医疗设施提升项目(一包)中标公告